
前面主要分析了以页为最小单位进行内存分配的伙伴管理算法,这对于内核对内存的管理比较简单,同时较大程度上避免了内存碎片的问题。而实际上对内存的申请却不是每次都申请一个页面的,通常是不规则的,大小不一的,并且远小于一个内存页面的大小,此外更可能会频繁地申请释放这些内存。
明显每次分配小于一个页面的都统一分配一个页面的空间是过于浪费且不切实际的,因此必须充分利用未被使用的空闲空间,同时也要避免过多地访问操作页面分配。基于该问题的考虑,内核需要一个缓冲池对小块内存进行有效的管理起来,于是就有了slab内存分配算法。每次小块内存的分配优先来自于该内存分配器,小块内存的释放也是先缓存至该内存分配器,留作下次申请时进行分配,避免了频繁分配和释放小块内存所带来的额外负载。而这些被管理的小块内存在管理算法中被视之为“对象”。
Slab内存分配算法是最先出现的;后来被改进适用于嵌入式设备,以满足内存较少的情况下的使用,该改进后的算法占用资源极少,其被称之为slob内存分配算法;再后来由于slab内存分配算法的管理结构较大且设计复杂,再一次被改进简化,而该简化改进的算法称之为slub内存分配算法。当前linux内核中对该三种算法是都提供的,但是在编译内核的时候仅可以选择其一进行编译,鉴于slub比slab分配算法更为简洁和便于调试,在linux 2.6.22版本中,slub分配算法替代了slab内存管理算法的代码。此外,虽然该三种算法的实现存在差异,但是其对外提供的API接口都是一样的。
创建一个slab的API为:
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *))
——其中name为slab的名称,size为slab中每个对象的大小,align为内存对齐基值,flags为使用的标志,而ctor为构造函数;
销毁slab的API为:
void kmem_cache_destroy(struct kmem_cache *s)
从分配算法中分配一个对象:
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
将对象释放到分配算法中:
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
除此之外,该分配算法还内建了一些slab(2^KMALLOC_SHIFT_LOW – 2^KMALLOC_SHIFT_HIGH)用于不需要特殊处理的对象分配。除了上面列举的分配和释放对象的接口,实际上对用户可见的接口为kmalloc及kfree。鉴于slub分配算法的优势,接下来则不对slab进行深入分析,主要分析slub分配算法。
首先鸟瞰全局,由下图进行入手分析slub内存分配算法的管理框架:
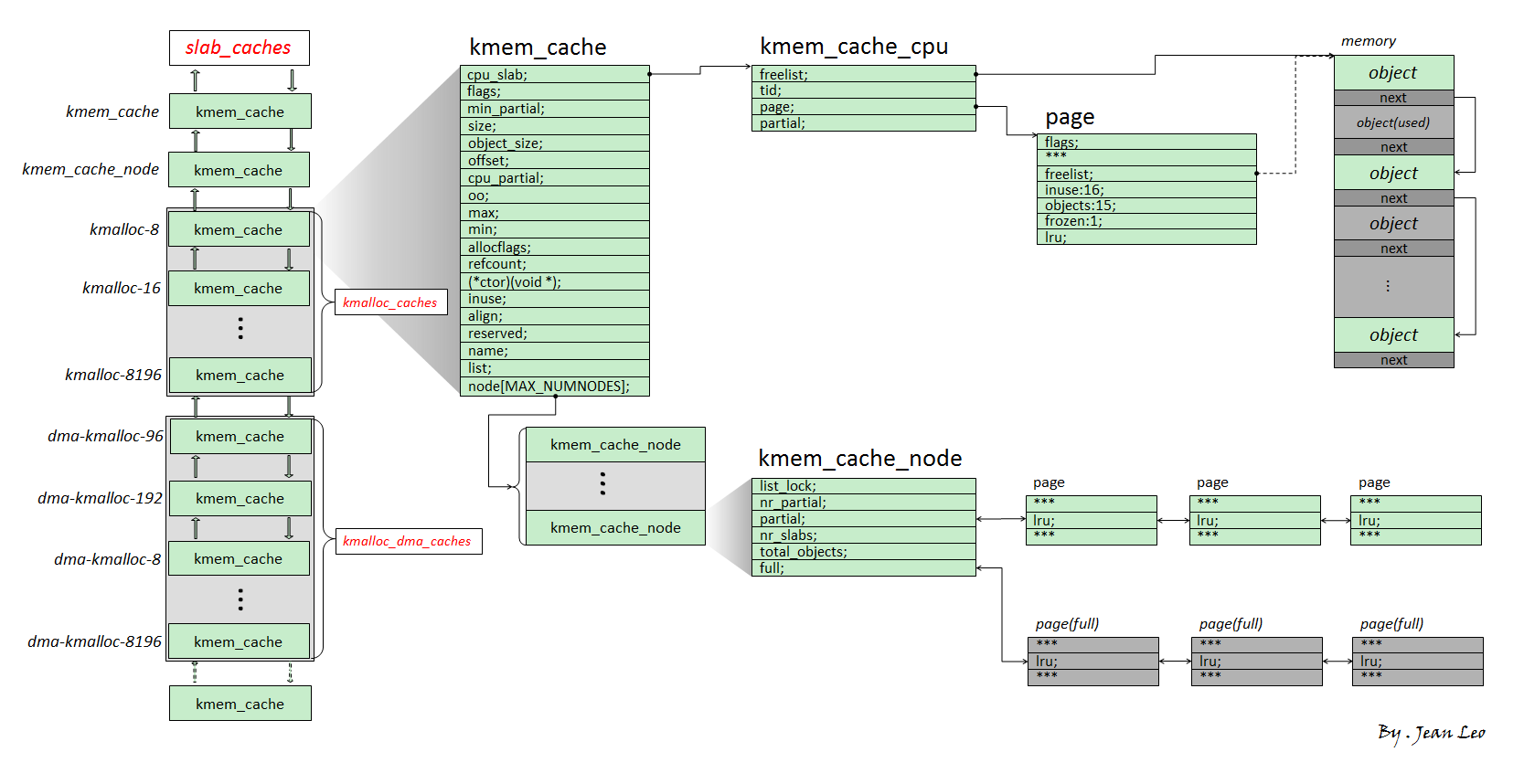
沿用slab算法对对象及对象缓冲区的称呼,一个slab表示某个特定大小空间的缓冲片区,而片区里面的一个特定大小的空间则称之为对象。
Slub内存分配算法中,每种slab的类型都是由kmem_cache类型的数据结构来描述的。该结构的定义为:
【file:/include/linux/slub_def.h】
/*
* Slab cache management.
*/
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; /*每CPU的结构,用于各个CPU的缓存管理*/
/* Used for retriving partial slabs etc */
unsigned long flags; /*描述标识,描述缓冲区属性的标识*/
unsigned long min_partial; /**/
int size; /* The size of an object including meta data */ /*对象大小,包括元数据大小*/
int object_size; /* The size of an object without meta data */ /*slab对象纯大小*/
int offset; /* Free pointer offset. */ /*空闲对象的指针偏移*/
int cpu_partial; /* Number of per cpu partial objects to keep around */ /*每CPU持有量*/
struct kmem_cache_order_objects oo; /*存放分配给slab的页框的阶数(高16位)和
slab中的对象数量(低16位)*/
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min; /*存储单对象所需的页框阶数及该阶数下可容纳的对象数*/
gfp_t allocflags; /* gfp flags to use on each alloc */ /*申请页面时使用的GFP标识*/
int refcount; /* Refcount for slab cache destroy */ /*缓冲区计数器,当用户请求创建新的缓冲区时,SLUB分配器重用已创建的相似大小的缓冲区,从而减少缓冲区个数*/
void (*ctor)(void *); /*创建对象的回调函数*/
int inuse; /* Offset to metadata */ /*元数据偏移量*/
int align; /* Alignment */ /*对齐值*/
int reserved; /* Reserved bytes at the end of slabs */
const char *name; /* Name (only for display!) */ /*slab缓存名称*/
struct list_head list; /* List of slab caches */ /*用于slab cache管理的链表*/
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
#endif
#ifdef CONFIG_MEMCG_KMEM
struct memcg_cache_params *memcg_params;
int max_attr_size; /* for propagation, maximum size of a stored attr */
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
int remote_node_defrag_ratio; /*远端节点的反碎片率,值越小则越倾向从本节点中分配对象*/
#endif
struct kmem_cache_node *node[MAX_NUMNODES]; /*各个内存管理节点的slub信息*/
};
上面各个成员的意义,可以参考里面的注释,而这里主要关注的是cpu_slab和node成员。
其中cpu_slab的结构类型是kmem_cache_cpu,是每CPU类型数据,各个CPU都有自己独立的一个结构,用于管理本地的对象缓存。具体的结构定义如下:
【file:/include/linux/slub_def.h】
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */ /* 空闲对象队列的指针 */
unsigned long tid; /* Globally unique transaction id */ /* 用于保证cmpxchg_double计算发生在正确的CPU上,并且可作为一个锁保证不会同时申请这个kmem_cache_cpu的对象 */
struct page *page; /* The slab from which we are allocating */ /* 指向slab对象来源的内存页面 */
struct page *partial; /* Partially allocated frozen slabs */ /* 指向曾分配完所有的对象,但当前已回收至少一个对象的page */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
至于kmem_cache_node结构:
【file:/mm/slab.h】
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock; /*保护结构内数据的自旋锁*/
#ifdef CONFIG_SLAB
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial; /*本节点的Partial slab的数目*/
struct list_head partial; /*Partial slab的双向循环队列*/
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
该结构是每个node节点都会有的一个结构,主要是用于管理node节点的slab缓存区。
Slub分配管理中,每个CPU都有自己的缓存管理,也就是kmem_cache_cpu数据结构管理;而每个node节点也有自己的缓存管理,也就是kmem_cache_node数据结构管理。
对象分配时:
- 当前CPU缓存有满足申请要求的对象时,将会首先从kmem_cache_cpu的空闲链表freelist将对象分配出去;
- 如果对象不够时,将会向伙伴管理算法中申请内存页面,申请来的页面将会先填充到node节点中,然后从node节点取出对象到CPU的缓存空闲链表中;
- 如果原来申请的node节点A的对象,现在改为申请node节点B的,那么将会把node节点A的对象释放后再申请。
对象释放时:
- 会先将对象释放到CPU上面,如果释放的对象恰好与CPU的缓存来自相同的页面,则直接添加到列表中;
- 如果释放的对象不是当前CPU缓存的页面,则会吧当前的CPU的缓存对象放到node上面,然后再把该对象释放到本地的cache中。
为了避免过多的空闲对象缓存在管理框架中,slub设置了阀值,如果空闲对象个数达到了一个峰值,将会把当前缓存释放到node节点中,当node节点也过了阀值,将会把node节点的对象释放到伙伴管理算法中。
这里只是做了简单的概要说明,而实际上由于面对的场景复杂,所以实现上有更多值得品味的处理细节。